Welcome back to PyGinners! Today, we’re diving into the describe method in Pandas, a powerful tool for summarizing your data. Whether you’re new to Python or just getting started with data analysis, this guide will walk you through everything you need to know.
What is Pandas?
The powerful describe method relies on Pandas. Pandas is a popular Python library for data manipulation and analysis. It provides data structures and functions needed to work efficiently with structured data, like tables. Pandas is essential for data analysis because it allows you to load, manipulate, and analyze large datasets with ease.
Why Do You Need Pandas?
- Data Handling: Pandas makes it easy to load and manipulate large datasets.
- Data Cleaning: It offers functions to handle missing data, duplicates, and other data issues.
- Data Analysis: With Pandas, you can perform complex data analysis and modeling.
- Integration: Pandas integrates well with other data science libraries like NumPy, Matplotlib, and Scikit-Learn.
- Ease of Use: It provides an intuitive and powerful way to work with data through its DataFrame and Series data structures.
Getting Started
Before we dive into the code, make sure you have Pandas installed. If you haven’t installed it yet, you can do so using pip:
pip install pandasDataset
The dataset we’re using is the “Global Air Quality” dataset from Kaggle. You can download it here. It contains information about air quality from various cities around the world. The columns in the dataset are as follows:
- City: The city where the data was collected.
- Country: The country where the city is located.
- Date: The date when the data was recorded.
- PM2.5: Concentration of particulate matter less than 2.5 micrometers.
- PM10: Concentration of particulate matter less than 10 micrometers.
- NO2: Concentration of nitrogen dioxide.
- SO2: Concentration of sulfur dioxide.
- CO: Concentration of carbon monoxide.
- O3: Concentration of ozone.
- Temperature: Ambient temperature in degrees Celsius.
- Humidity: Relative humidity percentage.
- Wind Speed: Wind speed in meters per second.
This dataset provides a comprehensive view of air quality metrics across different locations and times, making it perfect for practicing data analysis techniques.
Importing Pandas and Loading Data
First, we need to import the Pandas library and load our dataset. For this example, we’ll use the CSV file named ‘global_air_quality_data_10000.csv’.
# Import the pandas library
import pandas as pd
# Load the dataset into a DataFrame
df = pd.read_csv('global_air_quality_data_10000.csv')
Inspecting the First Few Rows
To get a quick look at the data, we can use the head method, which displays the first five rows of the DataFrame by default. This helps us understand the structure and contents of the dataset.
# Display the first five rows of the DataFrame
df.head()
The output will show the first five rows of your dataset, which might look something like this:
Using the describe Method
Now, let’s explore the describe method. This method provides a summary of statistics for numerical columns in your DataFrame.
# Use the describe method to describe the data
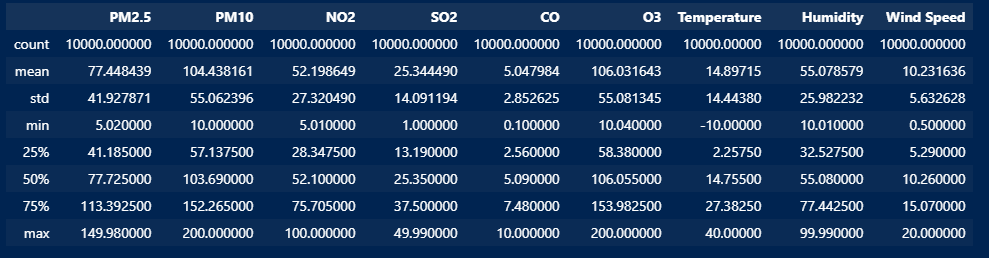
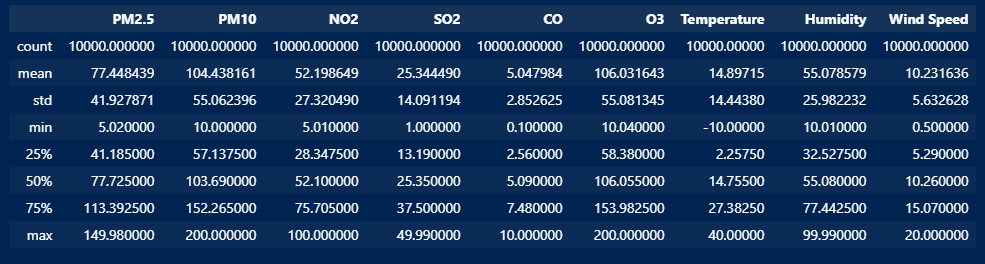
df.describe()The output will show various statistics for each numerical column in the dataset:
Understanding the Output
Let’s break down what each statistic means:
- count: The number of non-null entries in each column.
- mean: The average value of each column.
- std: The standard deviation, which measures the spread of the data.
- min: The minimum value in each column.
- 25%: The 25th percentile (first quartile), which indicates that 25% of the data falls below this value.
- 50%: The 50th percentile (median), which is the middle value of the data.
- 75%: The 75th percentile (third quartile), which indicates that 75% of the data falls below this value.
- max: The maximum value in each column.
Putting It All Together
Here’s the complete code with comments explaining each step:
# Import the pandas library
import pandas as pd
# Load the dataset into a DataFrame
df = pd.read_csv('global_air_quality_data_10000.csv')
# Display the first five rows of the DataFrame to understand its structure
df.head()
# Use the describe method to get a summary of statistics for the numerical columns
df.describe()
Conclusion
The describe method in Pandas is a powerful tool for summarizing the statistical properties of your dataset. It provides an easy way to understand the distribution, central tendency, and variability of your data.
By following this guide, you should now have a good understanding of how to use the describe method in Pandas. Try it out with your own data and see how it can help you gain insights quickly!
Stay tuned for more beginner-friendly tutorials on PyGinners. Happy coding!